

Incident response (IR) templates make it simple to customize your response plan. As such, they’re important foundational documents in a digital forensics and incident response initiative. They’re also easier to choose and customize than you might think. We’re offering a few customizable examples to get you started.
What is an Incident Response Plan (IRP)?
An IRP is a structured set of instructions that give directions for teams before, during, and after a security breach in order to minimize impact, speed recovery, and prevent future breaches. At their core, they include:
- Information on how to detect breaches
- How they’ll respond to the breach and to stakeholders
- Steps they’ll take to recover
However, key components of an IRP include more detail than these three primary areas. Typical IRP templates cover the entire incident lifecycle, spelling out:
- Policies: Procedures, tools, and infrastructure best practices in cybersecurity. These can include defining roles and responsibilities for individuals and teams in terms of handling various aspects of cybersecurity but also post-incident communication.
- Detection Rules: Determining whether events are security incidents, how they’re detected and logged, verified, how teams are alerted, and what governs their type and speed of response.
- Containment Procedures: How companies will limit the scope of an incident, isolating affected systems and preventing spread.
- Eradication: Paths to eliminating the root cause of an incident, from removing malware to patching systems and addressing insider threats.
- Recovery: Restoring systems and services along with operations, making sure the incident is addressed and updating IRPs to prevent similar future incidents.
- Post-Mortem Analyses: Reviewing the incident for lessons learned to understand overall organization strengths and weaknesses regarding cybersecurity.
Incident response templates offer a semi-structured outline so companies can fill in their custom assets, teams, and structures, creating an individual plan pre-populated with all the crucial components.
Runtime and Container Scanning with Upwind
Upwind helps organizations get to the bottom of incidents. With runtime-powered container scanning features, you get real-time threat detection, contextualized analysis, remediation, and root cause analysis that’s 10X faster than traditional methods.
Getting the Most Out of Incident Response Templates
Incident response templates help teams know they’re covering foundational issues, but none are perfect. By definition, they’re general structures that can’t account for the unique specificities of any real-life organization or tech stack, let alone both.
Teams that can find and contain a breach within 30 days save more than $1 million compared to those needing the organizational average of 166 days to accomplish the same feat.
IRPs are a tool that must be optimized to serve teams best. As a result, teams must make templates their own. What does that look like? Here’s a step-by-step guide.
Get Specific
Templates aren’t meant to be used out of the box. Start by making alterations based on your organizational structure, specific assets, systems, and unique threats.
Example: A healthcare organization may customize its template to include steps on isolating systems that handle protected health information (PHI) and prioritize threats to systems that contain sensitive patient data.
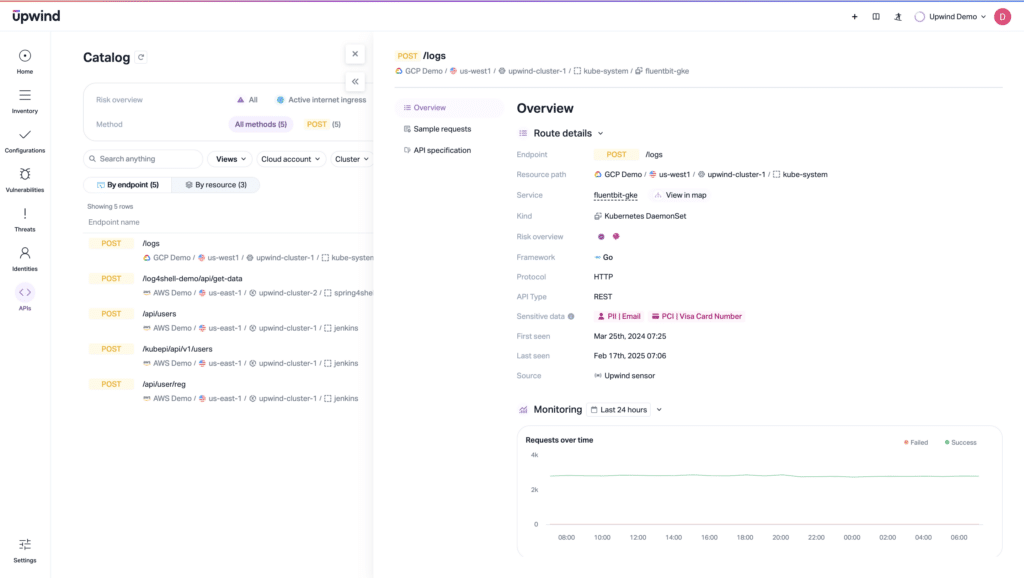
Think Cloud
It’s modern architectures that have made the threat landscape increasingly complex. Response plans need to match this landscape. Make sure your template accounts for your architecture and points to, or includes, playbooks and workflows that aren’t rooted in traditional IT, but in the realities of cloud computing. For instance, account for ephemerality or multi-cloud setups in your plans.
Example: An organization with multi-cloud deployments can adapt its template to include processes for monitoring and responding to threats in both AWS and Azure platforms, for example, analyzing logs from each in a unified dashboard.
Go Beyond DevSecOps
Customize the template based with input from, and details on roles for, HR teams, communications, PR, legal, IT, and compliance. Incorporate how to coordinate cross-department efforts.
Example: An organization creates an incident response timeline based on the severity of the hypothetical threat, including roles across various functions and plans for their coordination linked to specific workflows post-incident.
Put the Template to the Test
Live in the template you’ve created to pinpoint its potential bottlenecks and gaps. Create tabletop exercises to get a feel for how your plan might look in real-world scenarios.
Example: An organization simulates a phishing attack and employs its incident response workflows to assess how well its tools, teams, and approaches work together to address the attack.
Incorporate Automation
Account for your existing stack and gaps you may fill as you build your incident response functions, and consider automating tasks that could slow response, like threat detection, containment triggers, and initial remediation efforts.
Example: An organization incorporates tools to isolate compromised containers and notify team members when threats are detected, eliminating the lag that comes from manual detection and response.
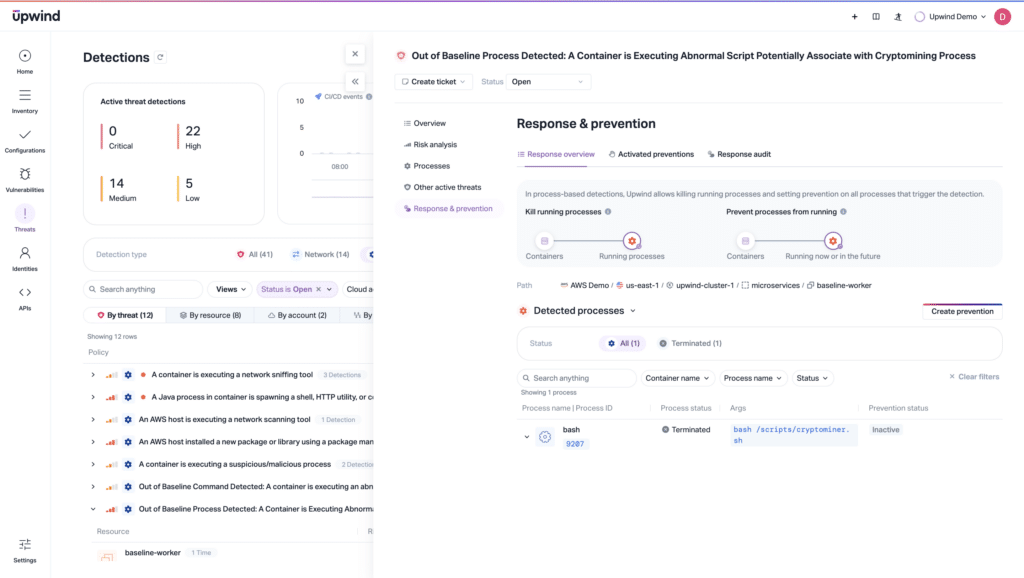
Define Your Metrics
Establish measurable goals for evaluating and responding to threats, like mean time to detect (MTTD) and mean time to respond (MTTR). Build them into your plan to improve over time.
How to Choose an Incident Response Template
Before teams can customize an incident response template, they’ll need to choose one. And which works best for their organization will differ on the basis of their needs and environment. Examining the table below is a start when evaluating the different templates available.
| Trait | Description | Questions to Ask |
| Comprehensiveness | Covers all key stages of incident response: preparation, detection, containment, eradication, recovery | Does the template include guidance for every phase of the incident response lifecycle? |
| Adaptability | Can be customized to fit your unique organizational structure, systems, and threat landscape. | Can this template be tailored for our specific industry or security stack? |
| Relevance for Cloud | Accounts for modern architectures, including multi-cloud, containers, and serverless environments. | Does the template address threats and workflows specific to cloud infrastructure? |
| Integration Potential | Can integrate with existing tools, workflows, and metrics for seamless implementation. | Will this template work with our current security tools, like runtime scanning or threat intelligence feeds? |
| Simplicity | Offers clear, actionable steps without unnecessary complexity. | Is the language clear and accessible for everyone involved in incident response, including legal and PR teams? |
| Regulatory Alignment | Addresses compliance requirements specific to industry or region. | Does this template align with compliance mandates like GDPR, HIPAA, or PCI DSS? |
| Real-World Validation | Proven in real-world scenarios or backed by authoritative sources. | Has this template been tested or used successfully by similar organizations? |
Many of these traits might make up an organization’s template checklist or wishlist. But they also represent some common compromises to contemplate: does the team value comprehensiveness more than simplicity, as these two often contradict? Is compliance more important than integration with existing workflows and tools?
10 Common Templates to Consider
To find the best resource for multiple types of organizations, we’ve outlined top incident response templates, with insights that differentiate them from the alternatives for easy evaluation.
NIST Computer Science Incident Handling Guide (SP 800-61 Rev. 2)
Globally recognized, highly detailed, and compliance-oriented, NIST is ideal for regulated industries. It’s strong in foundational guidance but less specific to cloud environments or modern architectures. NIST works best for enterprises, government agencies, and compliance-heavy industries.
Find it here: NIST SP 800-61
SANS Incident Handler’s Handbook
Actionable and user-friendly, SANS provides beginner-friendly insights without sacrificing depth. It’s simplistic compared to NIST but better suited for smaller teams and less mature security programs.
Find it here: SANS Handbook
AWS Incident Response Playbook
AWS offers a cloud-specific playbook with practical steps for AWS environments, addressing identity, EC2, and S3 incidents. It’s strong for AWS users but lacks general applicability to other cloud platforms.
Find it here: AWS Incident Response Playbook
Google Cloud Platform (GCP) Data Incident Response Process
This framework is designed to manage data incidents effectively. It’s tailored to GCP, making it less applicable to hybrid and multi-cloud environments compared to SANS or NIST, but could work well in organizations operating in GCP ecosystems.
Find it here: GCP Data Incident Response Process
University of Berkeley Security Incident Response Plan
Make a copy of this Google document, which includes information on organizational architecture, security incident confirmation and remediation, to get a head start on your security incident response. The Berkeley response template won’t help you move beyond traditional systems to focus on the cloud, nor will it coalesce multiple teams.
Find it here: University of Berkeley Incident Response Template
CISA Incident Response Plan Basics
CISA provides foundational guidance on developing an incident response plan, including clarifying roles and responsibilities and key activities before, during, and after a security incident. It’s not a detailed template, but it offers essential elements and considerations for creating an effective incident response plan, serving as a solid starting point.
Need authoritative guidance? This checklist will help organizations stay on the right track.
Find it here: CISA Incident Response Plan Basics
California Government Department of Technology
This 4-page outline is extremely detailed when it comes to traditional IT response, documenting discovery of incidents, contacting response teams, and creating tickets. But procedures to avoid breaches and playbooks to remediate the issue aren’t included, nor is working across teams.
Download it here: California Department of Technology Incident Response Plan Example
Government of Victoria (Australia) Incident Response Template
Victoria offers up an extremely comprehensive document that’s easy to amend, and includes everything from identification of breaches to the differences between procedures for internal vs. external communication. Appendices add valuable assets, like templates for evidence collection and internal memos.
Download it here: Victoria Government Cyber Incident Response Plan Template
National Institute of Health IR Template
The NIH template includes lengthy sections on systems and system ownership. It’s built for healthcare, so organizations operating outside that model may have more trouble reworking the template to meet their needs. However, it includes a balanced, moderate amount of detail on all parts of the incident detection and response process, making it a good source from which to add to more bare-bones templates.
Download it here: NIH Incident Response Template
University of Connecticut’s Incident Response Plan
This large public university’s incident response plan is high-level and difficult to amend for differing industries, but might serve as a model for organizations looking to put together a general policy for their own incident response for the first time, defining roles and policies at a basic level.
See it here: Incident Response Plan
Upwind Helps Teams Find and Respond Faster
As a comprehensive, modern CNAPP, Upwind can’t tell you which team members to call. However, it can support the teams in your IRP with real-time scanning powered by machine learning that captures anomalies and prioritizes high-risk behaviors or remediates them automatically. As a tool that uses runtime analysis to get to the root of incidents faster, Upwind can help your team find causes, fix issues, and get back to business.
To see it in action, schedule a demo.
FAQ
What are the 7 steps of an incident response plan?
The 7 steps of an incident response plan provide a structured approach throughout the chronology of an incident:
- Preparation before an incident
- Detection of an active incident
- Containment
- Eradication
- Recovery
- Lessons learned
- Testing and validation
How do you format an incident statement?
Incident response statements should include key facts about an incident formatted in straightforward, non-technical language so they’re understood by stakeholders, managers, and external parties alike. Include:
- The incident name or identifier, formatted according to organizational norms, often by the date and type of incident.
- The date and time of the incident.
- A high-level, one-sentence summary of what occurred and where in the system, the cause, and the result — for instance, exposed customer data. Include information on business disruption if applicable.
What does a good incident response plan look like?
A good incident response plan (IRP) is comprehensive enough to support teams and to be actionable but flexible enough to cover multiple incident types, and is tailored to the specific needs of an organization.
While the size and scope of a good IRP can differ, all good examples include:
- Clear objectives
- Defined roles and responsibilities
- Plans across multiple scenarios
- Steps to take to respond, in order
- Ways to classify incident severity and prioritize incidents by impact and urgency
- Guidance on communication internally and externally
- Information on compliance, if required
- Integration with existing tools, like a runtime-powered CNAPP to support ephemeral architectures and manage container security and real-time threat detection and prioritization
- Allowances for testing, updates, and lessons learned to improve this living document
What are incident response playbooks?
Incident response playbooks are predefined guides with steps to take in given scenarios to address incidents or recover from them. Unlike a general Incident Response Plan (IRP), playbooks offer specific and detailed instructions tailored to specific threats. They can be used alongside broader IRPs to coordinate roles and tasks during an incident.
How are vulnerabilities related to incident response?
Organizational plans to find and remediate vulnerabilities may seem distinct from those used to find and remediate active attacks. Vulnerabilities are, after all, unexploited, so their existence in software doesn’t rise to the level of a security incident. Further, examining software for vulnerabilities often happens before deployment, while attacks happen in the live environment.
Yet vulnerabilities are the windows through which attackers breach organizations, so organizations seeking to identify and eliminate vulnerabilities are likely to see far fewer active attacks. Those monitoring workloads at runtime for the most risky vulnerabilities can head off attacks that only emerge at runtime, too, and incorporate their newfound insight into better future builds, too. Runtime monitoring can also uncover attacks on undiscovered vulnerabilities, called zero-day vulnerabilities.





