

Extended Berkeley Packet Filter (eBPF) is emerging as a cornerstone of cloud-native management, enhancing observability and enabling sandboxed programs to operate directly within the Linux kernel. For Kubernetes, where managing distributed, ephemeral workloads at scale is inherently complex, eBPF offers a solution to some of the platform’s biggest challenges. By working directly at the kernel level, eBPF reduces the need for intrusive agents or sidecars, reducing operational overhead while delivering fine-grained insights and security enforcement.
Ultimately, eBPF represents more than just a tool; it’s a paradigm shift in how Kubernetes clusters are monitored and managed. This post uncovers how teams can harness its power while addressing the operational and strategic challenges that come with this cutting-edge technology.
Understanding eBPF for Kubernetes
eBPF is a Linux kernel technology that enables developers to run custom programs in the kernel space safely and efficiently. By extending the capabilities of the earlier BPF technology, eBPF allows deeper observability, security enforcement, and performance optimization without modifying the kernel itself.
Kubernetes is an open-source container orchestration platform that manages distributed, dynamic workloads. Its complexity and reliance on Linux make it a perfect candidate for eBPF, which addresses core challenges like visibility, performance, and security.
eBPF aids Kubernetes management with:
- Deep Observability: eBPF provides real-time insights into networking, CPU usage, memory, and system calls.
- Enhanced Security: With eBPF, teams can enforce fine-grained security policies directly in the kernel, securing pod-to-pod and external communications.
- Optimized Performance: eBPF operates with minimal overhead, reducing the need for intrusive agents or sidecars, and ensuring efficient Kubernetes cluster management.
eBPF improved on the earlier Berkeley Packet Filter (BPF) technology developed in 1993. The idea behind BPF was to equip the Linux kernel with tools for viewing, controlling, and filtering network traffic via the system call interface. Developers who used BPF could modify the system’s network policies dynamically, which was an approach to kernel programming at the time.
There were limitations, however. BPF was limited only to the Linux kernel networking subsystem; eBPF has no such limits and can attach to many resources that the Linux kernel provides, depending on the available hooks and kernel version. BPF supported only simple, network-oriented operations, but eBPF can extend the capabilities of a developed program with a wide variety of tools.
A massive community has grown around eBPF, culminating in many software development kits that make it easier to generate associated programs. The Linux Foundation’s eBPF project enjoys extensive community involvement.
eBPF allows developers to execute custom code in kernel space by following this process:
- They write an eBPF program.
- They load the program into the kernel. Typically, they do this with a user space tool, such as bpftool, that allows interaction with the eBPF framework.
- The program undergoes a verification process, which checks for issues like whether the program might attempt to access memory beyond its designated memory regions. eBPF program verification helps ensure that the program won’t destabilize the system.
- If the program passes the verification check, the kernel runs it using the code path specified in the program, and developers can view the output wherever the program was designed to expose it.
eBPF is vital in cloud computing because it enables fine-grained monitoring, security enforcement, and performance optimization at the system level without requiring significant kernel modifications.
Key Benefits of eBPF in Kubernetes
eBPF is emerging at a critical time when the need for observability in complex systems like Kubernetes has never been greater. Modern cloud-native environments are dynamic, distributed, and ephemeral, making traditional observability tools increasingly inadequate.
“We have more context of the current and historical runtime environment. Observability isn’t just about identifying what’s happening now; it’s about using that context to give meaningful, actionable insights before a problem escalates.”
-Joshua Burgin I CPO, Upwind
This intersection of complexity and demand for real-time insights has elevated eBPF as a tool in Kubernetes observability. Unlike traditional monitoring methods, eBPF operates directly within the Linux kernel, and this kernel-level integration enables visibility into system processes, network activity, and application behavior for actionable insights at the scale and speed Kubernetes demands.
The benefits of eBPF for Kubernetes go beyond observability, extending to performance optimization, security enforcement, and operational efficiency.
| Benefit | How does it work? |
| Enhanced Observability | Workloads. Network activity. System performance |
| Improved Security | Fine-grained policies. Anomaly detection. System-level protection against threats |
| Optimized Performance | Minimal overhead. Efficient packet processing. Identification of performance bottlenecks |
| Streamlined Operations | Eliminating intrusive agents. Making dynamic policy updates possible |
| Scalability | Adapts to Kubernetes clusters and dynamic, ephemeral workloads. |
| Cost Efficiency | Consolidates tools and reduces operational overhead with lightweight kernel integration |
eBPF’s ability to hook directly into the Linux kernel amplifies the benefits outlined above, particularly in observability, security, and performance. By operating at the kernel level, eBPF provides unparalleled access to system-level operations, enabling capabilities that external tools cannot match.
- Deep Observability:
Running directly in kernel space, eBPF provides visibility into workloads and clusters at a granular level. Development and security teams can gather real-time observability statistics, monitor system calls, and trace network traffic without requiring additional agents or instrumentation. That allows teams to troubleshoot faster and gain a comprehensive understanding of system behavior.
- Enhanced Security Monitoring:
eBPF dynamically delivers fine-grained security policies into the kernel, enabling better enforcement and monitoring. Unlike traditional solutions that operate at the application layer, eBPF operates closer to the source of activity, making it more effective for detecting anomalies and unauthorized actions.
- Performance Optimization:
eBPF’s ability to work within the kernel allows advanced performance monitoring without introducing significant overhead. Teams can analyze how Kubernetes clusters and nodes perform at a resource level, pinpoint bottlenecks, and optimize workloads efficiently.
- Reduced Operational Overhead:
Because eBPF is lightweight and integrated into the kernel, it eliminates the need for intrusive sidecars or agents. This reduction in complexity not only saves resources but also streamlines the operational workflows needed to maintain observability and security in Kubernetes environments.
This integration of eBPF into Kubernetes is made possible by its ability to operate seamlessly within the Linux kernel, leveraging key components like hooks, maps, and the eBPF virtual machine to deliver observability, security, and performance enhancements directly at the system level.
How eBPF Works in Kubernetes
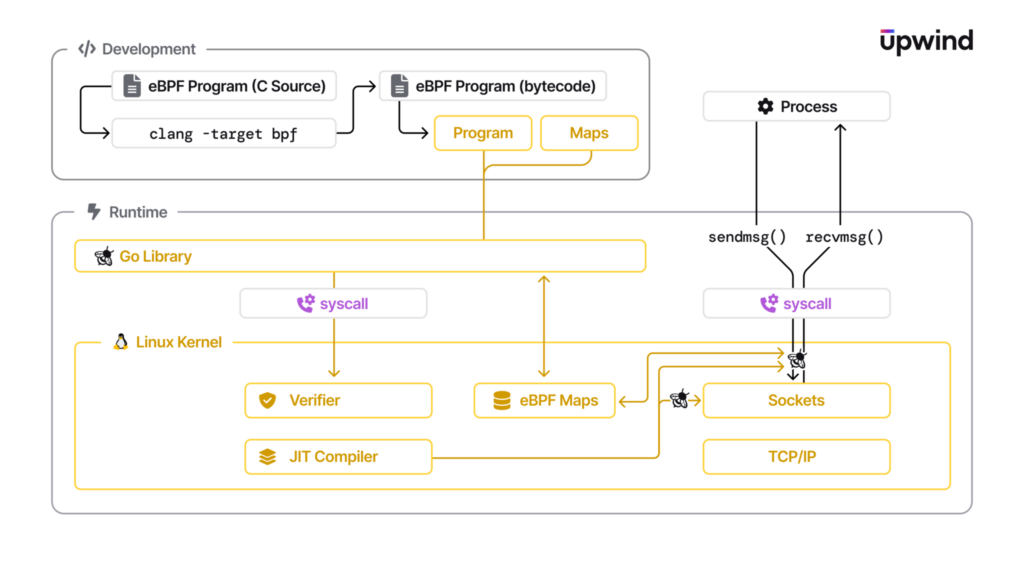
Linux has two memory spaces: kernel and userspace. The kernel is crucial to an operating system’s smooth functioning as it serves as the interface between hardware and the processes the OS runs. To protect system stability, the kernel only executes secure and trusted code. This restriction has historically limited the ability to dynamically add new functionality, but eBPF overcomes this limitation by enabling lightweight, sandboxed programs to run directly in the kernel space without requiring fundamental kernel modifications.
eBPF programs rely on several key components to function effectively within the kernel:
- eBPF virtual machine: A lightweight virtual machine that operates within the Linux kernel and executes eBPF bytecode.
- eBPF bytecode: The compiled form of an eBPF program that runs in the virtual machine.
- Verifier: The verifier validates eBPF bytecode for safety and compliance prior to executing it.
- Maps: These are key-value stores that enable eBPF programs and user-space applications to share and store data.
- Hooks: These are points in the Linux kernel where eBPF programs can be attached to monitor or modify behavior.
- XDP (eXpress data path): A high-performance path for data that allows eBPF programs to process packets at the driver level.
- BPF type format (BTF): This provides type information to make eBPF programs easier to write and understand.
- bpftrace: This is a high-level tracing language for eBPF that simplifies collecting data from the kernel.
- Libraries: eBPF libraries provide helper functions for the program.
Because Kubernetes has Linux underpinnings, eBPF can integrate tightly with the platform. This provides specific benefits for organizations seeking to enhance the observability of their Kubernetes clusters and operations more broadly.
Although eBPF is designed to be highly efficient, certain types of eBPF programs can still introduce performance overheads. Monitor the impact of these programs on system performance to ensure they’re properly optimized.
Primary Use Cases for eBPF in Kubernetes
As Kubernetes environments grow increasingly complex, eBPF’s ability to operate directly within the Linux kernel makes it increasingly desirable. Its core use cases span observability, security, performance, and network management — providing Kubernetes teams with granular insights and controls that traditional tools cannot match. Here’s a deeper look into each use case:
- Network observability and management: eBPF facilitates granular network monitoring, crucial for maintaining performance and identifying issues in real time. For instance, eBPF can track packet flows at various OSI layers, enabling operators to visualize traffic flow in and out of a Kubernetes cluster.
Open-source tools like Pixie leverage eBPF to automatically capture metrics like HTTP/gRPC requests, database queries, and network statistics without modifying applications. This capability allows developers and operators to trace requests from start to finish across the stack, which is invaluable for debugging and performance monitoring.
- Security monitoring and enforcement: eBPF enhances security by enforcing policies that are dynamically inserted into the Linux kernel, thereby enabling fine-grained control over packet processing. This is particularly useful for implementing Kubernetes network policies, which can dictate how pods communicate with each other and the outside world.
- Performance profiling and tracing: By tracking metrics about workload performance on a process-by-process level, eBPF excels at helping Kubernetes admins monitor the performance not just of applications as a whole, but of individual containers and microservices. If you want to know how your app is performing or pinpoint performance bottlenecks, eBPF is your friend.
- Traffic routing and filtering: For generic traffic filtering and performance management, eBPF is a powerful tool. By tracking TCP connections and associating them with processes accessing the network, eBPF gives you granular visibility into which network resources your containers, Pods and so on are using.
- Container and pod statistics: eBPF, in general, is known to give users in-depth visibility of the K8 systems. When Linux 4.10 was launched, a hierarchical grouping system for the container and pod levels was developed. eBPF could then provide network statistics for each of these groups and thus give complete details of the functioning of different pods and containers.
Implementing eBPF in Kubernetes
Because eBPF allows teams to run custom code inside the Linux kernel space of each Kubernetes node, using programs written in eBPF is fairly straightforward. From an operational standpoint, development teams need to:
- Determine what information to collect. eBPF empowers developers to collect virtually any kind of data that is available to the kernel, so it can provide visibility into networking, CPU and memory usage, storage operations and more.
- Write an eBPF program that tells the operating system kernel to expose whichever type of data is desired.
- Deploy the eBPF program on a node or nodes in the cluster that have access to the necessary resources. Programs are typically deployed via Kubernetes mechanisms like DaemonSets to ensure scalability and automation.
- Data is then collected and fed into analytics and/or visualization tools to gain a deeper understanding of what’s happening in the clusters.
The ability to collect almost any type of information by deploying code directly on nodes is part of what makes eBPF so powerful in Kubernetes. eBPF saves you from having to deploy a bunch of Kubernetes monitoring agents and collect scattered log files across various nodes.
There are three main ways that eBPF can be deployed on Kubernetes:
- Manual implementation approaches: Manual deployments are fairly simple and can be done on the nodes, but the problem is that teams need direct access to individual nodes. This makes it tough to automate and scale.
- DaemonSet deployments: Using DaemonSet means it’s possible to automate eBPF deployment across all nodes, or on select nodes. However, teams then have to create DaemonSets, which adds to the complexity of the Kubernetes implementation.
- Observability platform with eBPF built-in: A platform with eBPF built-in is the simplest way to deploy eBPF across the entire Kubernetes implementation. The problem is that not all observability platforms fully leverage eBPF.
eBPF vs Traditional Solutions
eBPF is often superior to other observability tactics, such as sidecar patterns and legacy monitoring tools. Sidecar patterns, in particular, add unnecessary complexity to Kubernetes. After all, deploying a new container alongside other containers just means more containers to orchestrate and manage.
Legacy monitoring tools come with similar challenges. They often operate within the userspace instead of the kernel space, for less insight but all the same management overhead. eBPF’s ability to function within the kernel space means that it can gain deeper insight into what’s happening behind the scenes in Kubernetes rather than gathering incomplete and inaccurate data from around different containers.
Optimized eBPF programs come with less performance degradation than sidecars or traditional monitoring tools. Overall, eBPF observability is very lightweight and easy to deploy. Organizations get the insight they need without adding complexity and weight to their Kubernetes instance.
Get Cloud Visibility with eBPF and Upwind
Upwind takes eBPF to the next level by integrating it directly into the Upwind Cloud Native Application Protection Platform. With real-time threat detection at scale, the Upwind eBPF sensor scans 30GB of container images using just 3% of their size, delivering fast, lightweight intelligence that detects advanced attacks and protects runtime environments from malicious processes.
Take the next step in securing your Kubernetes workloads with Upwind. Discover how our eBPF-powered platform delivers the observability, security, and performance your teams need to thrive. Get a demo today and experience the future of Kubernetes security.
FAQ
What is the difference between BPF and eBPF?
The Berkeley Packet Filter (BPF) was originally developed for filtering and controlling network traffic within the Linux kernel, limited to basic networking tasks. eBPF (Extended BPF) expands these capabilities to almost any kernel subsystem, enabling advanced observability, security, and performance optimization. Unlike BPF, eBPF includes safety features like program verification and supports dynamic, runtime execution of complex programs with minimal overhead.
How does eBPF differ from Cilium in Kubernetes environments?
eBPF is a kernel technology that allows teams to run small programs directly within Linux. Cilium is an open-source Kubernetes networking solution that leverages eBPF to provide high-performance network security and observability.
What insights can eBPF provide into encrypted traffic?
With eBPF, development, security, and operations teams can monitor network packets in detail to identify bottlenecks and traffic patterns. The technology traces system calls and kernel events for insight into application behavior, and traffic regardless of whether it’s encrypted or not.
What are the performance implications of using eBPF in production?
eBPF is designed to be lightweight and efficient, operating directly in the Linux kernel to minimize overhead. However, some performance implications can arise:
- Kernel-Level Overhead: Running eBPF programs in the kernel can consume CPU and memory resources, especially if the programs are not optimized or handle high volumes of data, such as packet filtering or syscall tracing.
- Resource Contention: eBPF programs that process large amounts of data or attach to frequently invoked kernel hooks (e.g., network packets or syscalls) can impact system performance if improperly scoped.
- Verification Time: The kernel’s verification process for eBPF programs ensures safety but can slightly delay deployment in some scenarios.
- Concurrency Risks: High concurrency environments (like Kubernetes clusters) can exacerbate resource usage if eBPF programs are not carefully managed or scaled properly.
The design of implementations can mitigate performance impacts. For example, by tailoring eBPF use specifically for runtime threat detection and observability, Upwind minimizes unnecessary overhead.




